Amino acid sequences provide the molecular instructions for peptide and protein structure. In laboratory research, understanding how a linear sequence gives rise to local conformation, three-dimensional organization, physicochemical behavior, and biological activity is essential for peptide design, synthesis, characterization, and application. Even short peptides can show complex structural preferences, while larger polypeptides may fold into highly organized domains stabilized by many weak interactions and, in some cases, covalent cross-links.
This article reviews the relationship between amino acid sequence and peptide structure, with emphasis on the chemical features that govern folding, stability, analytical behavior, and functional interpretation.
What Is an Amino Acid Sequence?
An amino acid sequence is the ordered arrangement of amino acid residues in a peptide or protein chain. By convention, sequences are written from the amino terminus, or N-terminus, to the carboxyl terminus, or C-terminus. This directionality reflects the way peptides are biosynthesized on ribosomes and how synthetic peptides are commonly described in research documentation.
Each residue in a sequence contributes a backbone unit and a side chain. The peptide backbone contains repeating amide bonds, while side chains provide chemical diversity. These side chains influence charge, hydrophobicity, steric constraints, hydrogen bonding, aromatic interactions, metal binding, and covalent modification potential. As a result, sequence is not only a record of residue identity; it is a determinant of molecular behavior.
One-Letter and Three-Letter Amino Acid Codes
Amino acid sequences are commonly represented using one-letter or three-letter codes. For example, glycine can be written as G or Gly, alanine as A or Ala, and tryptophan as W or Trp. One-letter codes are compact and frequently used in databases, bioinformatics, and sequence alignments. Three-letter codes are often used when clarity is important, such as in peptide synthesis reports or structural annotations.
Modified residues, D-amino acids, noncanonical amino acids, terminal caps, and post-translational modifications may require expanded notation. For example, an N-terminal acetyl group, a C-terminal amide, phosphorylated serine, or disulfide connectivity should be specified explicitly because these features can substantially alter structure and function.
Peptide Bonds and Backbone Geometry
Amino acids are linked by peptide bonds formed between the carboxyl group of one amino acid and the amino group of the next. The resulting amide bond has partial double-bond character due to resonance, which restricts rotation and makes the peptide bond largely planar. This constraint is a fundamental reason why peptide chains adopt defined conformational preferences rather than behaving as freely rotating polymers.
Although the peptide bond itself is relatively rigid, rotation is possible around the adjacent backbone bonds, commonly described by the phi and psi torsion angles. The allowable combinations of these angles are influenced by steric and electronic constraints and are often visualized using a Ramachandran plot. Certain amino acids have characteristic effects on backbone geometry. Glycine is highly flexible because its side chain is a hydrogen atom, whereas proline imposes rigidity due to its cyclic structure and can introduce bends or disrupt regular secondary structures.
N-Terminal and C-Terminal Effects
The termini of a peptide can influence solubility, charge state, enzymatic stability, and structure. At physiological pH, a free N-terminus is often positively charged and a free C-terminus is often negatively charged, although the exact ionization state depends on pH and neighboring residues. Terminal modifications such as acetylation or amidation can reduce terminal charge and may improve resistance to exopeptidase degradation. These modifications are common in research peptides when investigators aim to mimic native protein segments or reduce unwanted terminal effects.
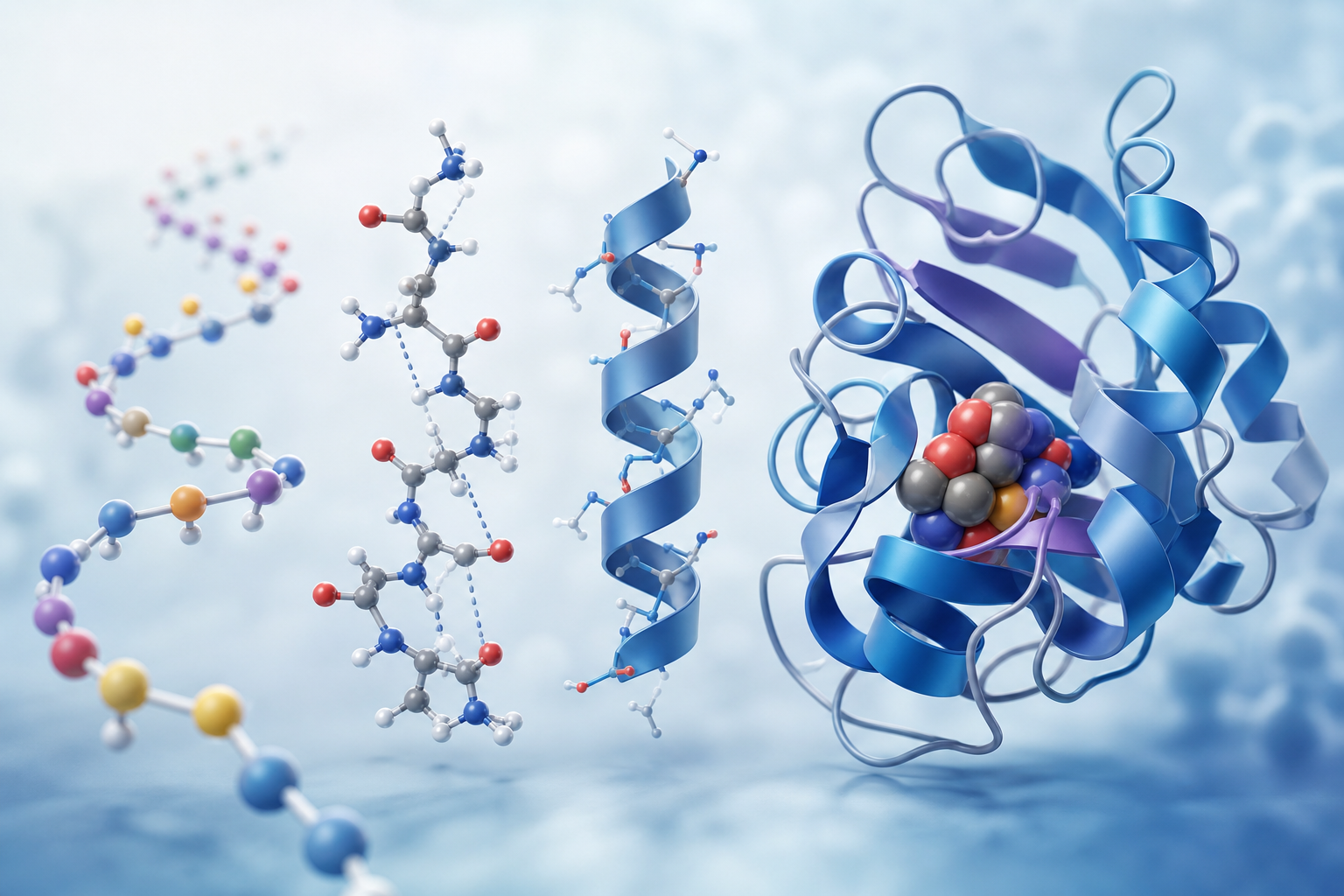
Levels of Peptide and Protein Structure
The relationship between sequence and structure is often described in hierarchical levels: primary, secondary, tertiary, and quaternary structure. For short synthetic peptides, secondary structure or local conformational preference may be the main structural feature of interest. For proteins and longer polypeptides, tertiary and quaternary organization become increasingly important.
Primary Structure
Primary structure is the amino acid sequence itself, including covalent features such as disulfide bonds, terminal modifications, and stable post-translational modifications. Because the primary structure determines the available chemical groups and backbone constraints, it provides the basis for higher-order structure. A single amino acid substitution can alter charge distribution, hydrophobic packing, protease susceptibility, or binding affinity.
Secondary Structure
Secondary structure refers to local, regularly repeating backbone conformations. The most common examples are α-helices, β-sheets, and turns. These structures are stabilized primarily by backbone hydrogen bonds, though side chains strongly influence whether a given segment is likely to adopt a particular conformation.
α-helices are favored by residues with suitable side-chain geometry and by sequences that support intrahelical hydrogen bonding and amphipathic organization. β-sheets often involve extended strands that hydrogen bond with neighboring strands, which may be parallel or antiparallel. Turns and loops allow chain reversal and are frequently enriched in glycine, proline, asparagine, and aspartic acid, although the sequence context is important.
Tertiary Structure
Tertiary structure describes the overall three-dimensional arrangement of a single polypeptide chain. It is stabilized by hydrophobic interactions, hydrogen bonds, salt bridges, van der Waals contacts, aromatic stacking, metal coordination, and disulfide bonds. In aqueous environments, hydrophobic residues often become buried in the interior of folded proteins, while polar and charged residues tend to remain solvent-exposed. However, active sites, binding interfaces, membrane-associated regions, and intrinsically disordered segments can deviate from these simplified patterns.
Quaternary Structure
Quaternary structure refers to assemblies of multiple peptide or protein chains. These may be identical subunits or distinct polypeptides. Sequence features at the interface, such as complementary charge, hydrophobic patches, and specific hydrogen-bonding patterns, determine whether oligomerization is stable and specific. For research involving peptide assemblies, coiled-coils, amyloid-forming sequences, or multimeric protein complexes, quaternary interactions can be central to function.
How Sequence Determines Peptide Structure
No single rule fully predicts structure from sequence in all contexts, but several principles are broadly useful. The distribution of hydrophobic, polar, charged, aromatic, and conformationally constrained residues strongly influences folding and association. The solvent, pH, ionic strength, concentration, temperature, and presence of membranes or binding partners can also shift structural equilibria.
Hydrophobicity and Amphipathicity
Hydrophobic residues such as leucine, isoleucine, valine, phenylalanine, and methionine tend to avoid water and can drive folding, aggregation, membrane association, or self-assembly. When hydrophobic and polar residues are arranged periodically, peptides may form amphipathic helices or sheets with one face oriented toward a hydrophobic environment and the other toward aqueous solvent. This pattern is common in antimicrobial peptides, membrane-binding segments, and protein interaction motifs.
Charge and Electrostatic Interactions
Charged residues influence solubility, long-range interactions, and binding to oppositely charged molecules. Lysine and arginine are commonly positively charged near neutral pH, while aspartate and glutamate are commonly negatively charged. Histidine has a side-chain pKa near physiological pH and can respond sensitively to modest pH changes. Electrostatic attractions can stabilize folded structures or molecular complexes, while electrostatic repulsion can reduce aggregation or destabilize compact conformations.
Disulfide Bonds and Covalent Constraints
Cysteine residues can form disulfide bonds under oxidizing conditions. Disulfide connectivity is particularly important in extracellular peptides, hormones, toxins, and constrained peptide libraries. Correct disulfide pairing can stabilize a defined fold, whereas incorrect pairing may produce heterogeneous products or reduced activity. For synthetic peptides containing multiple cysteines, orthogonal protecting groups or controlled oxidation strategies may be required to obtain the intended connectivity.
Proline, Glycine, and Conformational Flexibility
Proline and glycine have distinctive structural roles. Proline restricts backbone rotation and lacks a conventional amide hydrogen for backbone hydrogen bonding, making it a common helix breaker or turn-promoting residue. Glycine increases flexibility and is often found in tight turns, flexible linkers, or regions requiring minimal steric bulk. A sequence enriched in glycine and proline may be less likely to form stable α-helices or β-sheets, although context remains critical.
Peptide Structure in Solution and at Interfaces
Peptide structure is often environment-dependent. A sequence that is disordered in water may become helical in membrane-mimetic conditions, upon binding a receptor, or in the presence of trifluoroethanol. Similarly, peptide concentration can influence self-association or aggregation. For this reason, structural data should be interpreted in relation to experimental conditions.
Interfaces are especially important in peptide research. Membrane-active peptides may adopt amphipathic structures only when associated with lipid bilayers. Surface-immobilized peptides may display altered accessibility or orientation compared with free peptides in solution. Peptides used as antigens, affinity ligands, or biomaterial components may therefore require structural assessment under conditions that approximate the intended application.
Analytical Methods for Sequence and Structure Characterization
Reliable peptide research depends on appropriate analytical characterization. Sequence confirmation, purity assessment, molecular mass determination, and structural evaluation provide complementary information. The choice of methods depends on peptide length, complexity, modifications, concentration, solubility, and the question being addressed.
Mass Spectrometry and Chromatography
Liquid chromatography coupled with mass spectrometry is widely used to assess peptide identity and purity. Mass spectrometry confirms molecular weight and can help identify truncations, deletion sequences, oxidation, deamidation, or other modifications. Tandem mass spectrometry can provide sequence information through fragmentation patterns. High-performance liquid chromatography is commonly used to evaluate purity and separate closely related species, although chromatographic purity does not by itself prove correct sequence or structure.
Amino Acid Analysis and Edman Sequencing
Amino acid analysis provides quantitative information about residue composition after hydrolysis, while Edman degradation can determine N-terminal sequence for peptides with a free N-terminus. These methods remain useful in selected workflows, particularly for independent verification or quality control. However, they have limitations with blocked termini, certain modifications, long sequences, or residues that are degraded during hydrolysis.
Circular Dichroism, NMR, and X-Ray Crystallography
Circular dichroism spectroscopy provides a rapid assessment of secondary structure content and conformational changes under different conditions. Nuclear magnetic resonance spectroscopy can provide residue-level structural and dynamic information, particularly for peptides and smaller proteins in solution. X-ray crystallography can determine high-resolution structures when suitable crystals can be obtained. Cryo-electron microscopy is more common for larger complexes but may be relevant for peptide-associated assemblies or protein complexes containing peptide ligands.
Sequence Considerations in Peptide Design
When designing peptides for research, several sequence-level factors should be evaluated early. These include expected solubility, net charge, hydrophobic content, secondary structure propensity, aggregation risk, protease susceptibility, synthesis difficulty, and potential side reactions. Long hydrophobic sequences, multiple cysteines, repeated residues, and sequences prone to aspartimide formation, oxidation, or aggregation can present synthetic and analytical challenges.
Terminal modifications, incorporation of D-amino acids, cyclization, PEGylation, lipidation, or substitution with noncanonical residues may be used to alter stability, conformation, or binding properties. However, such modifications can also change biological activity, immunogenicity, assay compatibility, or analytical behavior. Design choices should be linked to a defined experimental objective and supported by appropriate controls.
Common Misinterpretations and Practical Limitations
A frequent misconception is that a short peptide corresponding to a protein segment will automatically adopt the same structure as it does in the full-length protein. In many cases, the native conformation depends on tertiary contacts, neighboring domains, membranes, cofactors, or binding partners that are absent in the isolated peptide. Another limitation is that computational predictions, while increasingly useful, require experimental validation, especially for flexible peptides, disordered regions, and modified sequences.
It is also important to distinguish between purity, identity, and functional conformation. A peptide may be chemically pure but structurally heterogeneous, or it may have the correct mass but contain positional isomers, incorrect disulfide pairing, or conformational states that affect performance. Orthogonal analytical methods are often necessary when structural precision is critical.
Conclusion
Amino acid sequence is the foundation of peptide structure, influencing backbone geometry, folding, stability, solubility, interactions, and biological function. Understanding the chemical properties encoded in a sequence helps researchers design peptides more effectively, interpret analytical data, and select suitable characterization methods. Because peptide structure is context-dependent, careful attention to modifications, environment, and experimental conditions is essential for reliable scientific conclusions.